
Stable Diffusion的基本原理
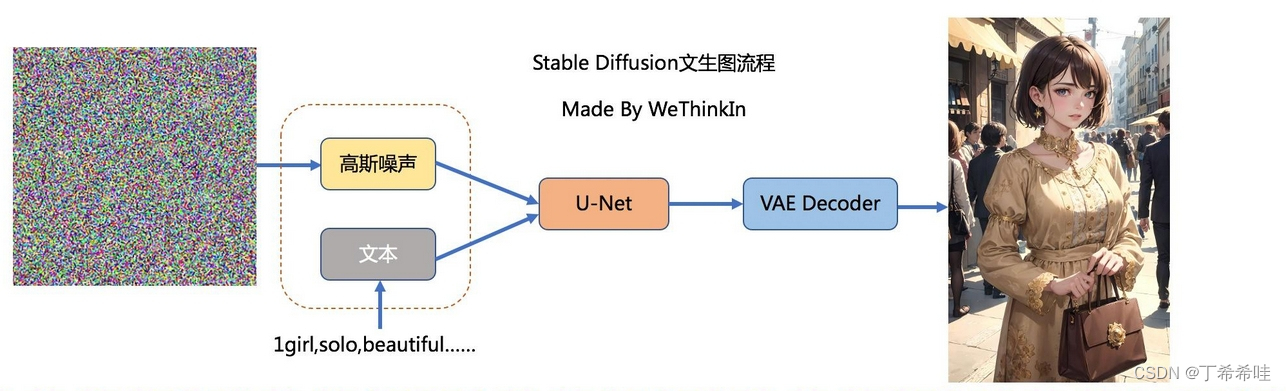
Stable Diffusion 基本原理
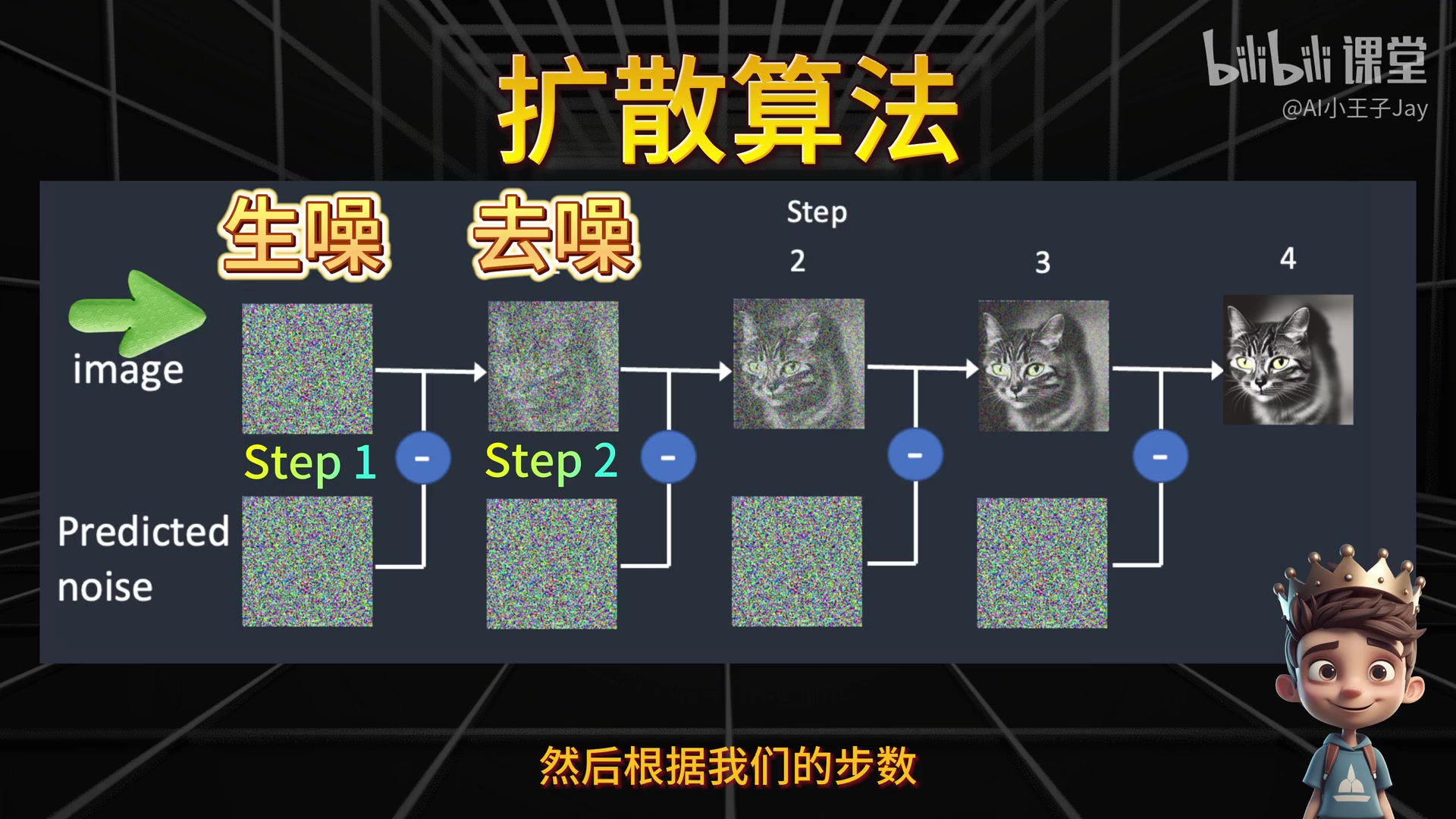
Stable Diffusion 中文译为"稳定的扩散":
- Stable:稳定
- Diffusion:扩散
整个 SD 系统基于扩散算法生成图像,其核心原理是"生噪到去噪"的过程:
- 正向扩散:增加噪声点(生噪)
- 反向扩散:消除噪声点(去噪)
在图像生成时,系统会:
- 先将图片铺满噪声点
- 根据设定的步数(steps)逐步降噪
- 通过删除噪声点最终形成目标图像
可以形象的想象为睁眼-眯眼-睁眼的过程
文本编码:CLIP 的作用
当输入提示词(如"One Beautiful Girl")时,AI 并不能直接理解人类语言。这类似于只会讲中文的人与只会讲英文的人交流,需要一个"翻译"环节。
在 AI 世界中,这个翻译就是 CLIP(Contrastive Language-Image Pre-training):
- CLIP 是文本编码器(Text Encoder)算法的一种
- 功能:将人类语言转换为计算机能理解的语言
- 本质:将文本信息转变为数字化描述
文本编码的过程:
- 计算机只能理解数字化描述
- CLIP 将人类语言转换为机器可读的描述
- AI 据此捕捉文本中的含义
- CLIP 算法基于模型训练经验,推断"美丽女孩"应具备的特征
K采样器
潜空间 (Latent Space) 压缩
文本编码后,计算机可理解的语言会进入 潜空间(Latent Space)。
为什么需要潜空间?
正常生成一张 512×512 像素的图片时:
- 每张图片有 RGB 三个通道
- 总数据量:512 × 512 × 3 = 786,432 个数据点
- 直接计算会消耗巨大算力资源
- 普通显卡几乎无法处理如此大的数据量
潜空间的压缩效果:
- 在潜空间内,数据被极度压缩
- 压缩后规格:64 × 64 × 4 = 16,384 个通道数据
- 极大降低了算力成本
- Latent Space 本质上是一个压缩过程
去噪过程与 U-Net
在潜空间内,U-Net 负责对随机种子生成的噪声图像进行引导去噪。
U-Net 的功能:
- 让图片去噪的关键组件
- 在潜空间内工作
- 配合采样器(Sampler)、CFG scale 等参数工作
随机种子的作用

为什么同样的关键词会生成不同的图片?
- 每次生图都是在随机种子内随机抽选数字
- 每个随机种子生成的噪声点不同
- 去噪后就会得到不同的图片
这在 MidJourney、Stable Diffusion Web UI 和 Comfy UI 中都有体现。
VAE 解码器
经过去噪后,图像已经在计算机世界中生成,但这还不是人类可识别的图像格式。
需要解码的原因:
- 压缩后的文件不能直接查看
- 计算机世界的向量对人类来说只是密密麻麻的数字
- 需要解压缩才能变成可视图像
VAE 解码器(Variational Autoencoder Decoder)的作用:
- 将计算机输出解码为人类可理解的图像
- 与编码器过程相反(编码器让计算机理解人类语言)
- 解码完成后,最终图像就生成了
完整流程总结
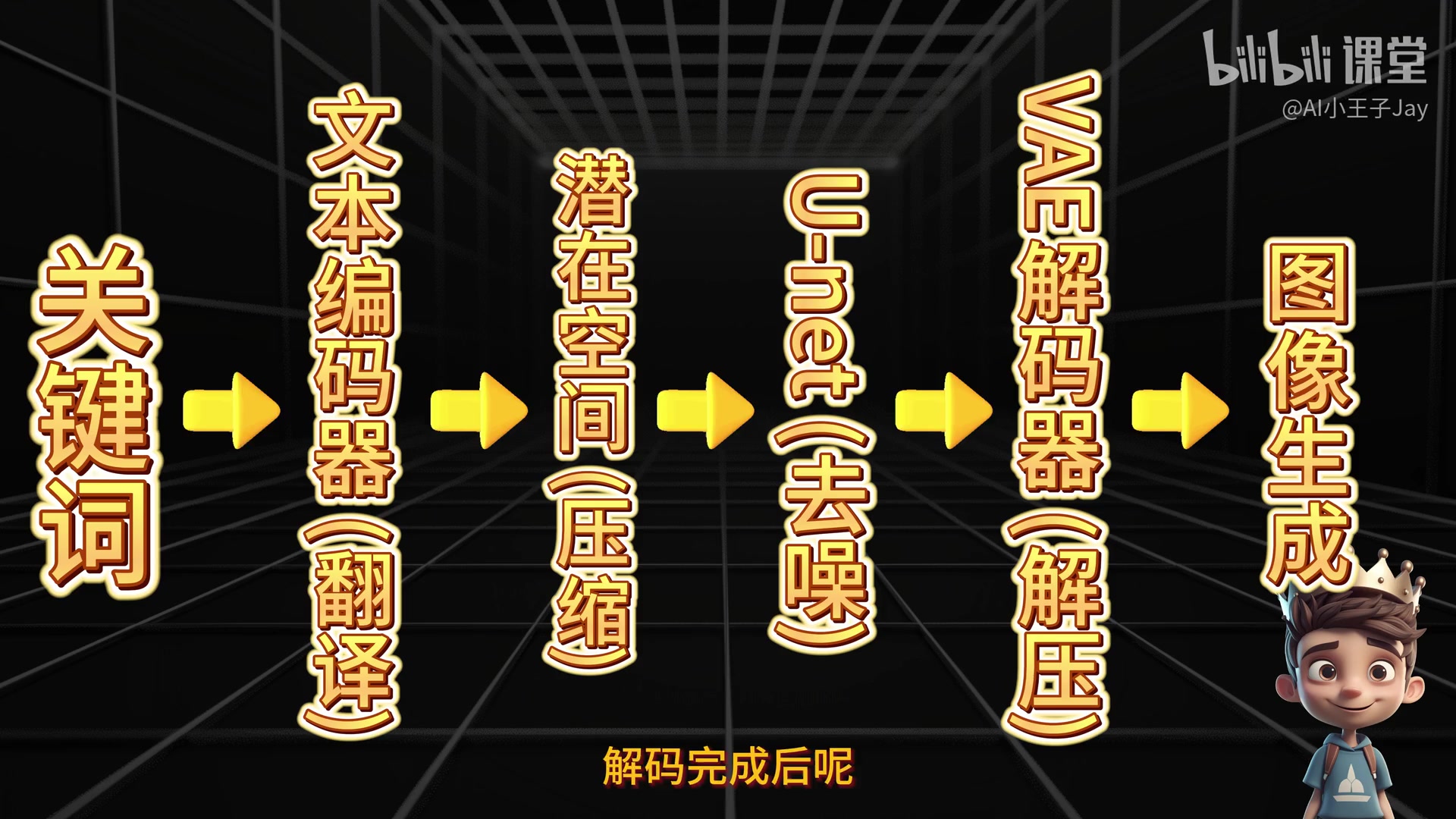
Stable Diffusion 的完整工作流程:
- 文本编码:CLIP 将人类语言转换为机器可读的数字化描述
- 潜空间压缩:将数据压缩到 Latent Space 降低计算成本
- 噪声生成:基于随机种子生成初始噪声
- 引导去噪:U-Net 在潜空间内根据文本引导进行去噪
- 解码输出:VAE 解码器将机器数据解码为人类可视图像
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 古月月仔的博客!
评论

