OpenPCDet模型的推理结果以字典形式输出,包含检测目标的类别、位置、尺寸等关键信息。不同模型输出结构类似,但具体字段可能略有差异。
output/kitti_models/pointrcnn/default/eval/eval_with_train/epoch_80/val/result.pkl中选取某一帧的结果示例,提取为json文件便于阅读:
| |
内容解读
name
含义:检测到的物体类别。
示例:["Car", "Pedestrian", "Pedestrian", ...]
说明:
- “Car” 表示检测到的物体是车辆。
- “Pedestrian” 表示检测到的物体是行人。
truncated
含义:物体被截断的程度。
示例:[0.0, 0.0, 0.0, ...]
说明:
取值范围为 [0, 1],0.0 表示物体未被截断,1.0 表示物体被完全截断。
occluded
含义:物体被遮挡的程度。
示例:[0.0, 0.0, 0.0, ...]
说明:
取值范围为 [0, 2],0.0 表示物体未被遮挡,1.0 表示物体被部分遮挡,2.0 表示物体被完全遮挡。
alpha
含义:物体的视角角度(观察角度)。
示例:[-4.0102105140686035, -1.6028798818588257, ...]
说明:
- 表示物体相对于相机的视角角度(以弧度为单位)。
- 取值范围为
[-π, π]。
bbox
含义:物体在图像中的 2D 边界框。
示例:[[0.0, 196.87057495117188, 410.6382141113281, 373.0], ...]
说明:
- 每个边界框的格式为
[x_min, y_min, x_max, y_max],表示边界框的左上角和右下角坐标。 - 坐标单位为像素。
dimensions
含义:物体的 3D 尺寸(长、宽、高)。
示例:[[4.10535192489624, 1.4689395427703857, 1.6220554113388062], ...]
说明:
每个物体的尺寸格式为 [length, width, height],单位为米。
location
含义:物体在相机坐标系中的 3D 位置(中心点坐标)。
示例:[[-2.7540218830108643, 1.6045180559158325, 4.157565593719482], ...]
说明:
- 每个物体的位置格式为
[x, y, z],单位为米。 - 坐标系为相机坐标系。
rotation_y
含义:物体绕相机坐标系的 y 轴的旋转角度(偏航角)。
示例:[-4.574054718017578, -1.476109504699707, ...]
说明:
单位为弧度,取值范围为[-π, π]。
score
含义:检测结果的置信度分数。
示例:[0.9997606873512268, 0.9978153705596924, ...]
说明:
取值范围为 [0, 1],1.0 表示检测结果非常可靠。
boxes_lidar
含义:物体在激光雷达坐标系中的 3D 边界框。
示例:[[4.406521797180176, 2.786322832107544, -0.915142297744751, 4.10535192489624, 1.6220554113388062, 1.4689395427703857, 3.003258228302002], ...]
说明:
- 每个边界框的格式为
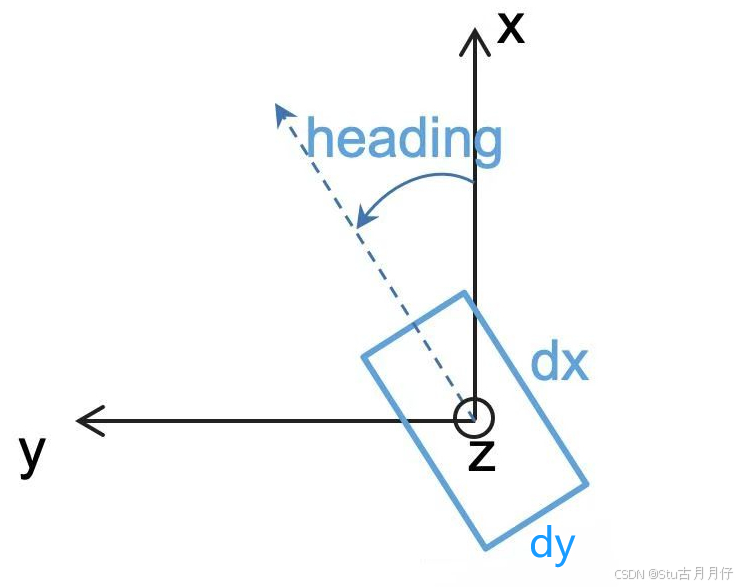
[x, y, z, length, width, height, ry],单位为米。 (x, y, z)表示边界框的中心点坐标。(length, width, height)表示边界框的尺寸。ry表示边界框绕激光雷达坐标系的 z 轴的旋转角度(偏航角),单位为弧度。
坐标系说明
相机坐标系:
- x 轴:向右(图像右侧)。
- y 轴:向下(图像底部)。
- z 轴:向前(相机光轴方向)。
激光雷达坐标系:
- x 轴:向前(车辆前进方向)。
- y 轴:向左(车辆左侧)。
- z 轴:向上(垂直于地面)。
数据对应关系
location 和 boxes_lidar:
location 是基于相机坐标系的,而 boxes_lidar 是基于激光雷达坐标系的。 如果需要将 location 转换到激光雷达坐标系,可以使用 KITTI 提供的外参矩阵。
bbox 和 boxes_lidar:
bbox 是物体在图像中的 2D 边界框,而 boxes_lidar 是物体在激光雷达坐标系中的 3D 边界框。
提取json文件的代码
有朋友留言问我是怎么把pkl文件提取出来的,附下面的代码供参考: 使用时记得替换路径
| |