文章概述了生成式AI在视觉内容领域的演进,从早期算法到VAE和GAN,再到当前主流的扩散模型,分析了其核心思想与特点,并指出AIGC正向更高分辨率、更丰富内容和更可控的方向发展。
随着人工智能以空前的速度不断发展, 生成式人工智能(artificial intelligence generated content, AIGC)重新定义了视觉内容的生成、制作和编辑过程, 彻底改变了我们感知和创造视觉内容的方式.
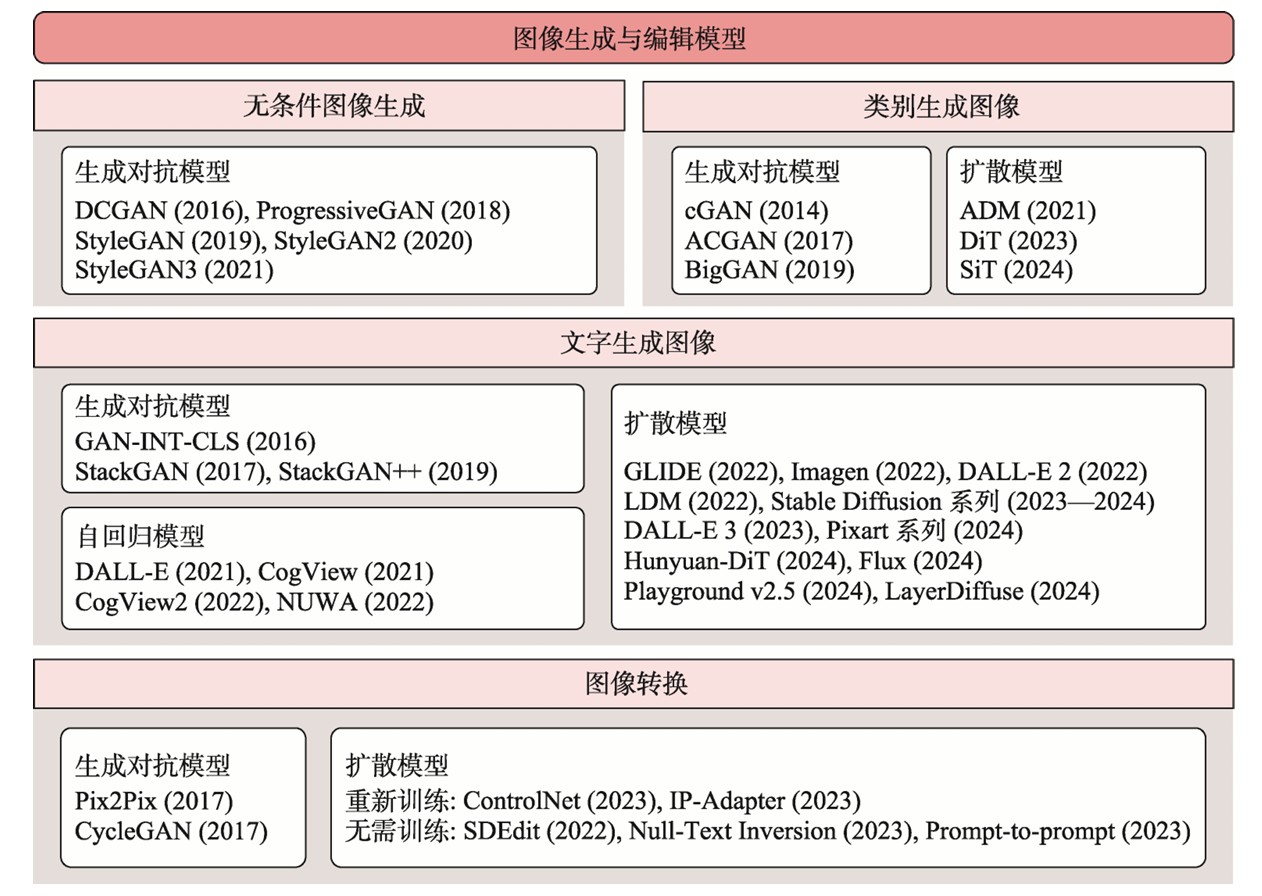
早期算法通常使用图像匹配或人工设计的生成规则合成简单的纹理或结构; 随后, 深度学习时代提出变分自编码(variational auto-encoder, VAE)和生成对抗网络(generative adversarial net work, GAN), 它们能够学习如人像、室内场景等典型的图像分布; 当前,涌现出了大型的扩散模型来 生成图像和更具挑战性的视频, 其生成的质量之高 甚至是人也难以区分真假. 从传统算法到 VAE 和 GAN, 再到扩散模型, AIGC 正在向更高分辨率、更丰富内容和更可控的生成方向演变.

图像生成模型
目前主流的图像生成模型大致可以分为以下四类:
| 模型类型 | 代表模型 | 核心思想 | 特点 |
|---|---|---|---|
| GAN(生成对抗网络) | StyleGAN、BigGAN、CycleGAN | 生成器与判别器对抗训练 | 图像质量高,但训练不稳定,控制性差 |
| VAE(变分自编码器) | VQ-VAE、DALL-E 1 | 编码为潜在变量再解码 | 稳定性好,但图像模糊,细节差 |
| Diffusion(扩散模型) | Stable Diffusion、DALL-E 2/3、Imagen | 去噪过程生成图像 | 图像质量高,控制性强,训练成本高 |
| 自回归模型 | Parti、ImageGPT | 像语言模型一样逐像素/块生成 | 可扩展性强,但生成速度慢 |
早期模型
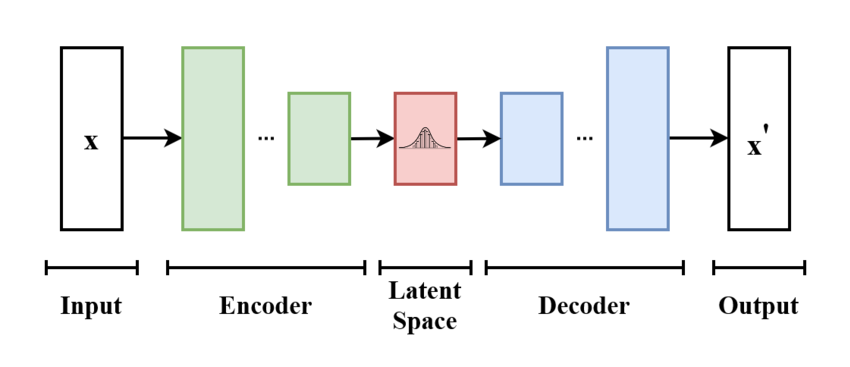
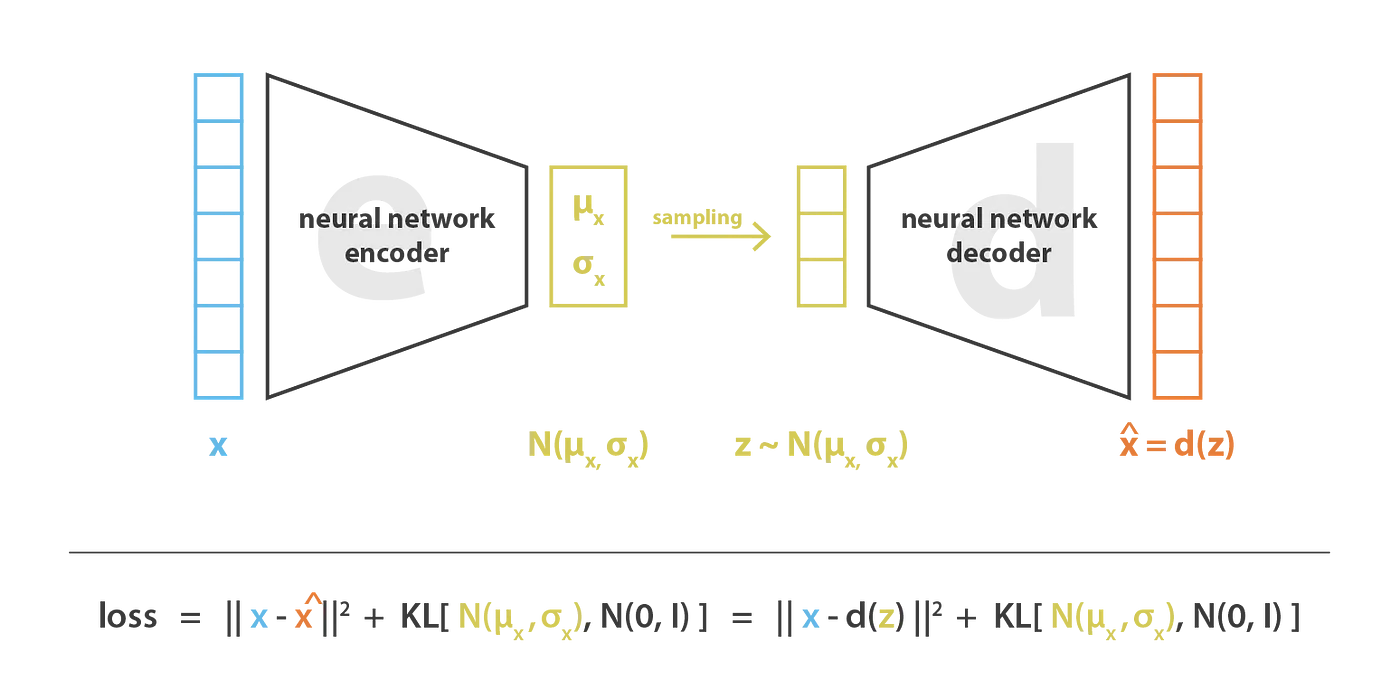
VAE——概率生成建模的开端
VAE(Variational Autoencoder) 是从“自编码器(Autoencoder)”演变而来的。 普通自编码器只是学会“压缩—还原”数据,而 VAE 把“隐空间”变成一个概率分布(通常假设为高斯分布),通过在这个分布中随机采样,就可以“生成”新的样本。
其核心结构包括:
Encoder(编码器):把输入图像 x 映射到隐变量 z,并学习其均值 μ 和方差 σ。
Decoder(解码器):从采样得到的 z 恢复出图像 $\hat{x}$
Loss 函数:由两部分组成:
- KL 散度:让隐变量分布接近标准高斯分布
- 重构误差:保证生成图像与输入图像尽可能一致
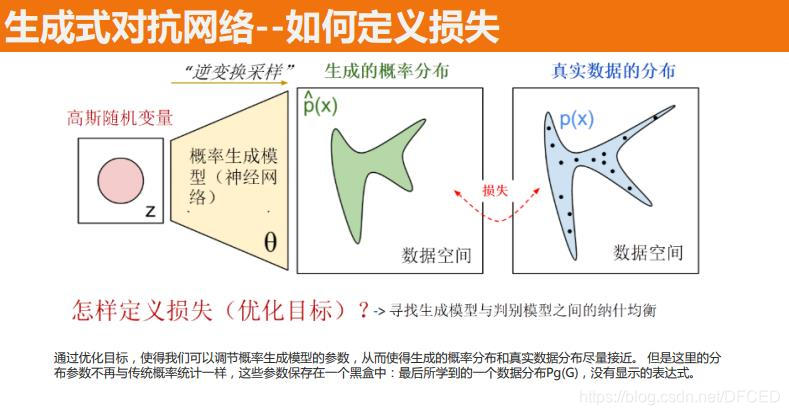
GAN——对抗博弈的艺术家
GAN(Generative Adversarial Network)由 生成器(Generator) 和 判别器(Discriminator) 组成,二者进行“博弈”:
- 生成器试图“伪造”真实图像
- 判别器试图区分“真图”与“假图” 两者相互促进,直到生成器骗过判别器为止。
这种机制能让 GAN 学习到极其逼真的数据分布。
其训练目标公式如下:
$$ \min_G \max_D V(D, G) = E_{x \sim p_{\text{data}}}[\log D(x)] + E_{z \sim p_z}[\log (1 - D(G(z)))] $$也就是让判别器尽量区分真伪,而生成器尽量“骗过”它。
自回归模型——逐像素预测的“语言模型式”生成
自回归模型(Autoregressive Models)的基本思想:
把图像看作一个序列:像素点或图像块按顺序出现。 模型通过条件概率分解:
$$ p(x) = \prod_i p(x_i | x_{文生图模型
自然语言是人类最常用的表达方式, 利用文字 生成图像非常符合用户的使用习惯和需求.只需要输入一段英文描述, 模型就能生成对应的图像, 并且最新的模型生成的内容细节和分辨率都得到显著提升. 然而, 要实现这一技术, 需要克服自然语言建模和图像生成2个方面的挑战.
早期文生图
早期文生图以GAN为主线:cGAN先做到64×64,加入坐标后升到128×128;StackGAN提出两阶段,先低分辨率再补细节,无额外条件也能出256×256,并用文本统计量缓解稀疏;StackGAN++把阶段扩成树状多生成器-判别器,同时做条件与无条件训练。 Transformer兴起后,DALL-E用离散VAE把256×256图像压成32×32 Token,自回归统一建模图文;CogView支持中文,CogView2引入分层生成提速;NÜWA提出3D Transformer,把语言、图像、视频一并覆盖。
扩散模型
GLIDE 首次把扩散模型用于文生图,对比了两种文本引导策略:依靠文本编码器提供分类器梯度的引导,以及完全不用分类器的引导。实验显示,无分类器引导得到的图像更逼真,也更贴合文本描述。GLIDE 在训练图文对齐时,同步更新文本编码器;而 Imagen 直接采用预训练且参数冻结的大模型作为文本编码器,省去了联合训练的开销。由于纯文本语料规模远大于图文对,该编码器事先在更广泛的语料上训练,具备更强的语言理解能力。为了输出 1024×1024 的高清图,Imagen 使用级联架构:先产生 64×64 的小图,再逐级上采样到 256×256,最终达到 1024×1024。
扩散模型是当前AI生图的核心技术,Stable Diffusion、DALL-E 2/3、Imagen 等都基于它。
扩散模型包括两个过程:
- 正向过程(Forward Process):将一张图像逐步加噪,直到变成纯噪声。
- 反向过程(Reverse Process):训练一个神经网络,从噪声中逐步去噪,恢复出图像。
!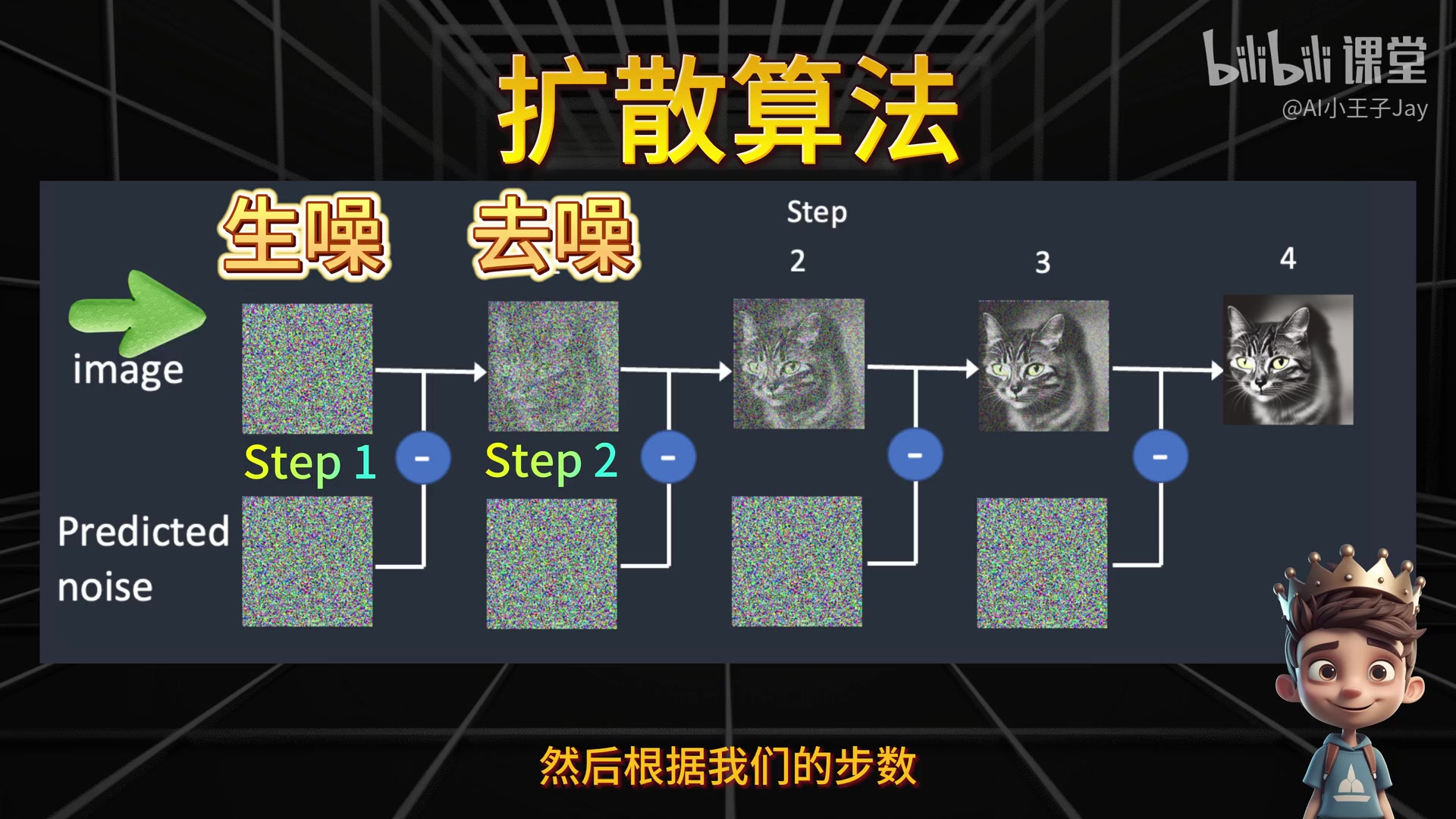
Tip 把图像“搅乱”成噪声,再学会“还原”出图像,可以形象的想象为睁眼-眯眼-睁眼的过程
除此之外,为了让生成的图像符合文本描述,生图模型还需要引入文本编码器(如 CLIP、T5),将文本转换为向量,指导去噪过程。
CLIP
对齐文本与图像表征是文生图等跨模态应用 的基础之一. **多模态感知模型 CLIP(contrastive language-image pre-training)**经过大量文本-图像配对数据的训练, 利用对比学习方法实现了文本与图像在统一表征空间中的对齐。
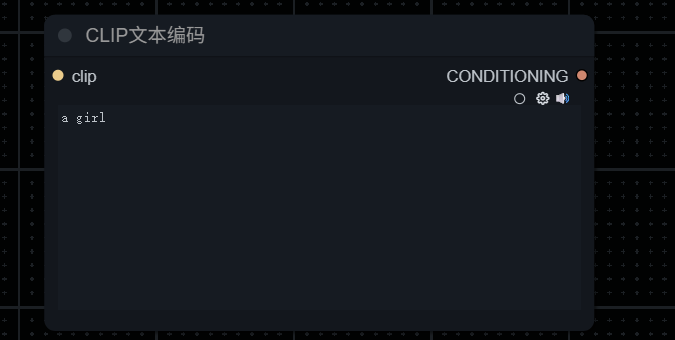
Note 当输入提示词(如"One Beautiful Girl")时,AI 并不能直接理解人类语言。这类似于只会讲中文的人与只会讲英文的人交流,需要一个"翻译"环节。
在 AI 世界中,这个翻译就是 CLIP(Contrastive Language-Image Pre-training):
- CLIP 是文本编码器(Text Encoder)算法的一种
- 功能:将人类语言转换为计算机能理解的语言
- 本质:将文本信息转变为数字化描述
文本编码的过程:
1.计算机只能理解数字化描述。2.CLIP 将人类语言转换为机器可读的描述。3.AI 据此捕捉文本中的含义。4.CLIP 算法基于模型训练经验,推断"美丽女孩"应具备的特征。
LDM(Latent Diffusion Model)
针对扩散模型在像素空间的训练与推理复杂度极高的问题, LDM采用编码器将 256×256×3 的图像由像素压缩为 32×32×4 隐变量, 并在隐空间进行扩散模型的训练与推理, 生成隐变量后通过解码器恢复为图像, 大幅降低了扩散模型的计算开销; 此外, 引入交叉注意力作为将文本等控制信息融入模型引导图像生成的方式.
基于 LDM, 诞生了知名的开源文生图模型Stable Diffusion系列. Stable Diffusion 1.x版本能够生成分辨率为512×512 像素的图像, Stable Diffusion 2.x 版本支持的分辨率上升到了768×768 像素. SDXL使用的参数量为Stable Diffusion 1 和Stable Diffusion 2 的 3 倍, 其针对模型训练时数据随机裁切造成的画面主体偏移, 以及图像不同宽高比难以适配深度学习架构并行计算的问题, 提出将图像裁切位置原宽高比作为生成条件提供给模型.
Stable Diffusion 架构
Stable Diffusion 是目前最流行的开源生图模型,其架构如下:
| 模块 | 功能 |
|---|---|
| Text Encoder | 将输入文本编码为语义向量(如 CLIP Text Encoder) |
| VAE(变分自编码器) | 将图像压缩到潜在空间(Latent Space),降低计算量 |
| U-Net | 在潜在空间中进行去噪,是生成过程的核心 |
| Scheduler | 控制去噪步骤的策略(如 DDIM、DPM++) |
SD架构的最大优势:在潜在空间中进行扩散,大幅降低计算成本,可在普通GPU上运行。这种加构也被称为潜在扩散模型(Latent Diffusion Model, LDM)
LDM 的核心思想就是:
先用一个自编码器(VAE)把图像压缩到一个低维潜在空间(Latent Space),再在这个小空间中进行扩散。
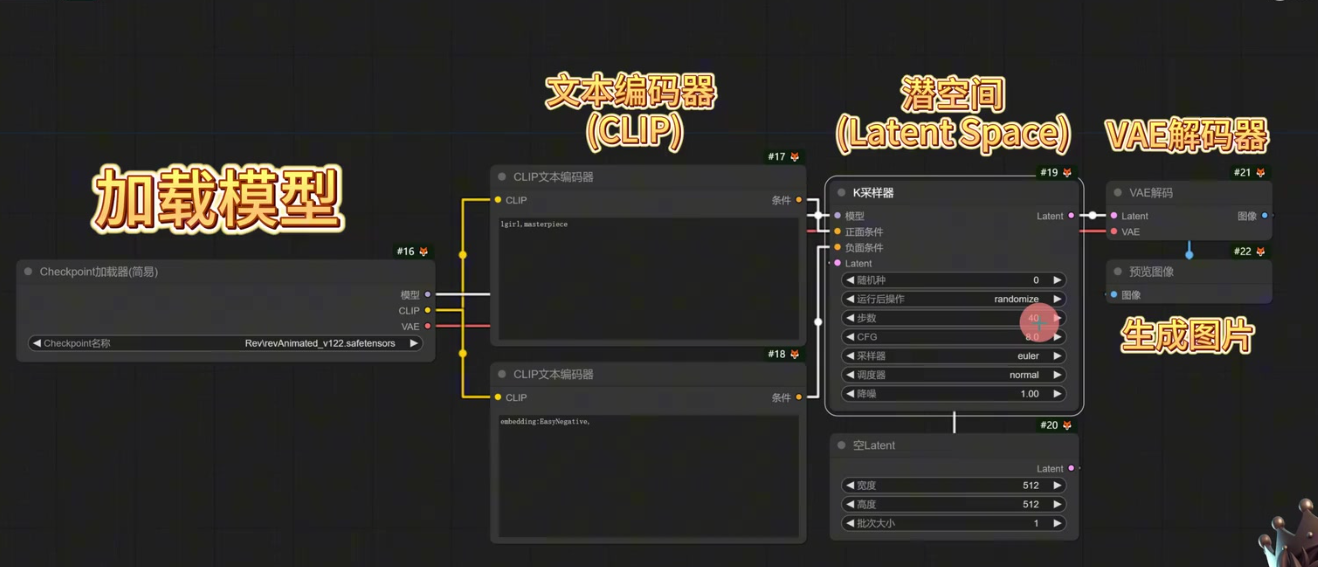
文本编码后,计算机可理解的语言会进入 潜空间(Latent Space)。
Note 为什么需要潜空间? 正常生成一张 512×512 像素的图片时:
每张图片有 RGB 三个通道,则其总数据量:512 × 512 × 3 = 786,432 个数据点。会直接计算会消耗巨大算力资源,普通显卡几乎无法处理如此大的数据量
潜空间的压缩效果:
在潜空间内,数据被极度压缩。压缩后规格:64 × 64 × 4 = 16,384 个通道数据,极大降低了算力成本,Latent Space 本质上是一个压缩过程
DiT架构
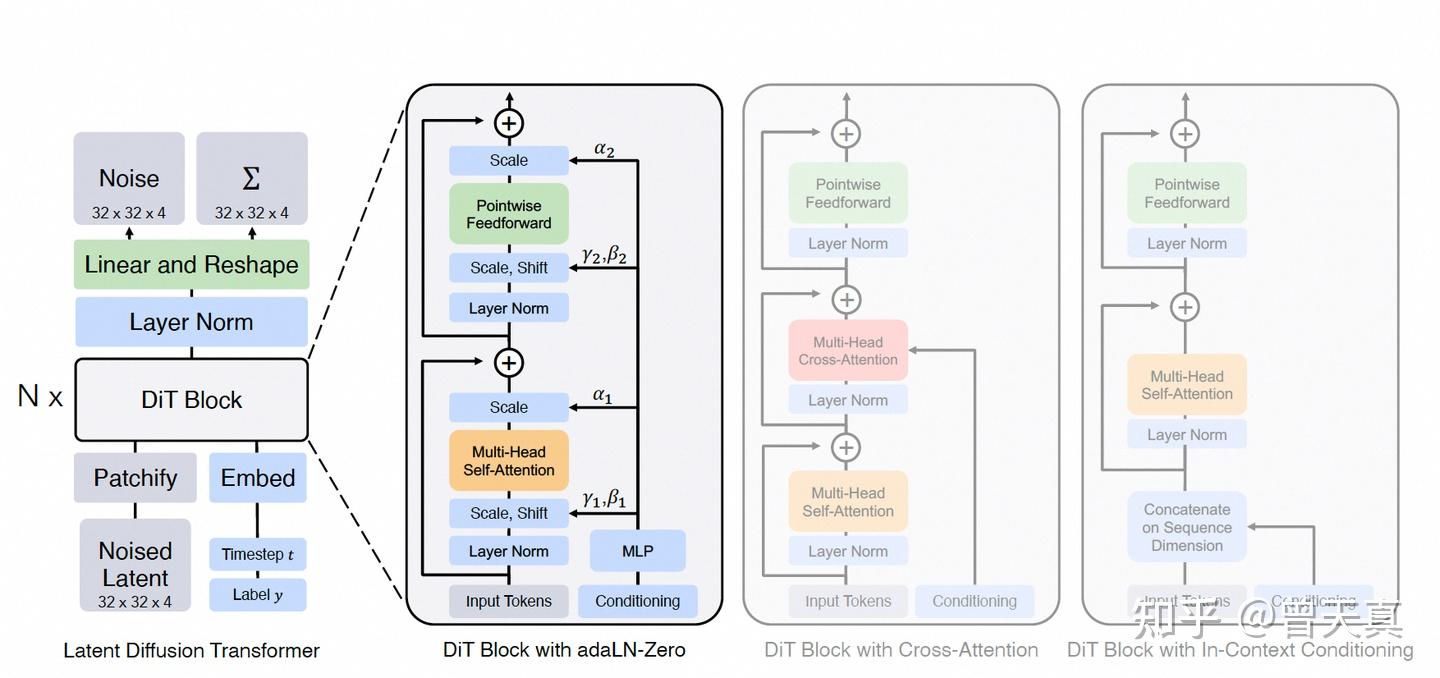
DiT,全称 Diffusion Transformer,是一种 用 Transformer 替代 U-Net 的扩散模型架构。 它最早由 MIT 和 Google Brain 团队在 2023 年提出(论文《Scalable Diffusion Models with Transformers》)。传统扩散模型(如 DDPM、Stable Diffusion)中,核心去噪网络是 U-Net 卷积架构;而 DiT 用纯 Transformer 模块来建模去噪过程,将图像生成转化为一个“视觉 token 的序列建模问题”。
得益于Transformer 在大规模视觉任务上更好 的扩展性, DiT架构被广泛使用.
Stable Diffusion 3采用多模态 DiT架构, 通过AdaLN和输入Token叠加2种方式引入控制条件, 由于图像和文本特征是完全不同的, 对这2种模态采用2 组独立的权重, 即图像和文字有其独立的Transformer层, 但同时进行注意力操作互相感知。
基于扩散模型的ControNet
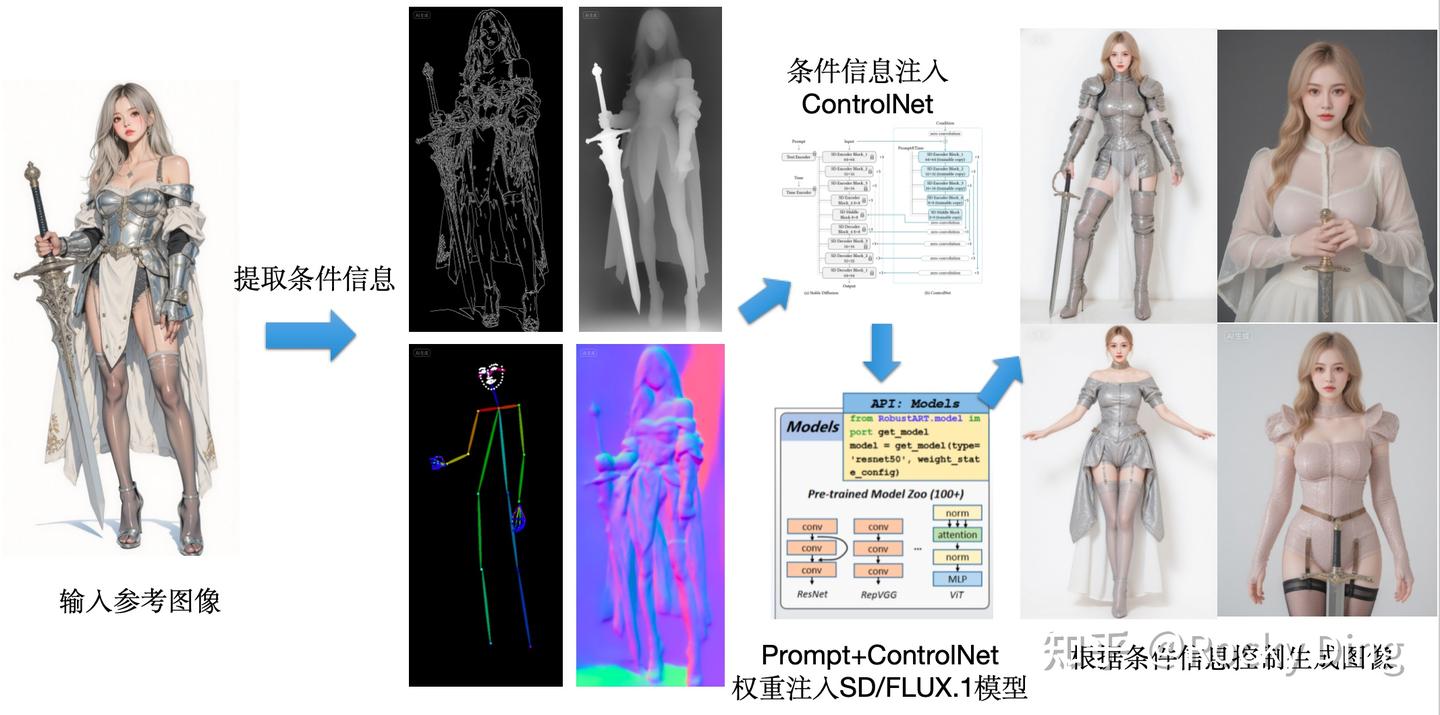
自2021年基于扩散模型的Stable Diffusion被提出后, 许多研究者开始研究利用Stable Diffu sion 进行更可控的生成. ControlNet能够根据用 户提供的条件图像(如边缘图、语义分割图)进行可控生成, 完成多样化的图像转换任务. ControlNet 使用预训练好的Stable Diffusion 的 U-Net 去噪网络作为特征提取网络进行条件图像的特征提取, 并通过零卷积层将提取出的条件图像特征注入 Stable Diffusion原始的U-Net去噪网络中充当生成时的引导. 由于特征提取网络和去噪生成网络具有相同的网络结构, 二者的特征差异较小, 因此更容易起到引导和约束生成的作用.
ControlNet做的就是这样一件事:它为扩散模型(如 Stable Diffusion/FLUX.1)提供一种额外的“约束”条件,引导AIGC大模型按照我们期望的构图、姿态或结构来生成图像,减少图像生成的随机性。

图像引导的图像生成模型IP-Adapter
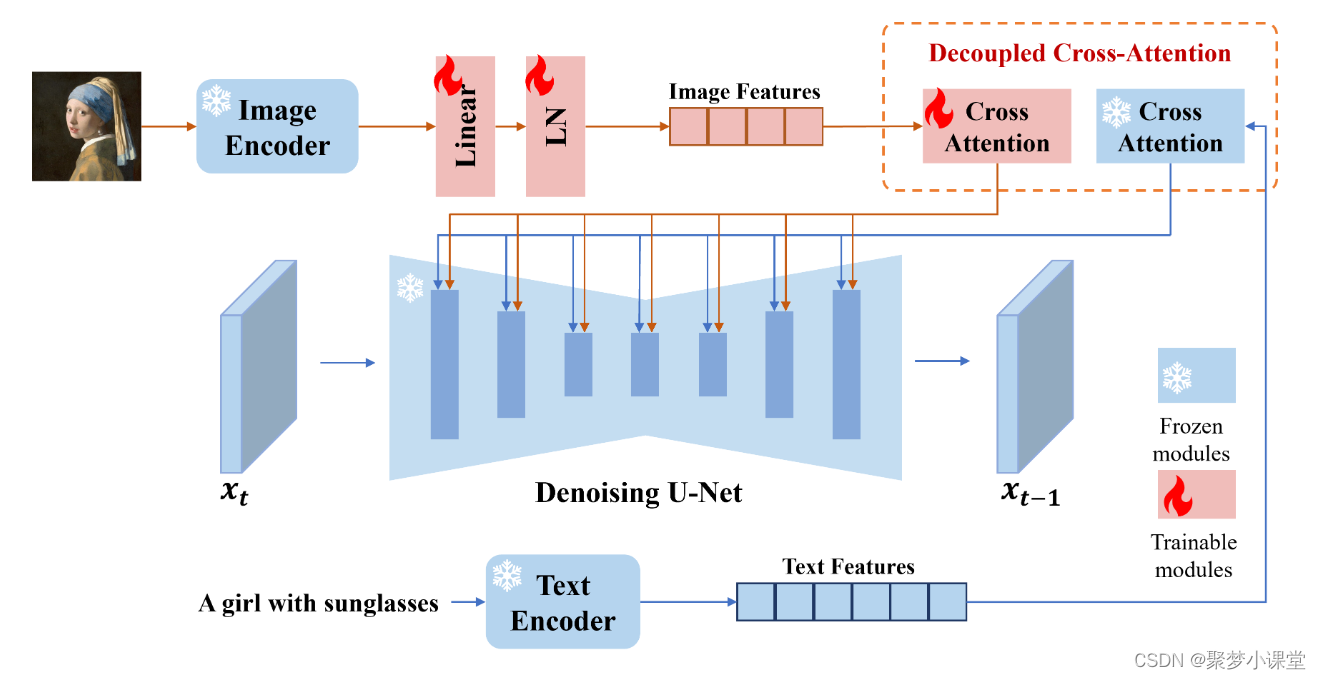
Stable Diffusion 的强大之处除了在于其经过大规模数据集的训练而达到高质量生成能力外, 更在于能够根据文本提示引导的可控生成能力. 为此, IP-Adapter设计了解耦的交叉注意力机制, 将条件图像按照原来文本提示的方式提供生成引导, 利用可以对齐视觉和语言的CLIP模型提取条件图像的特征, 并训练线性映射器完成交叉注意力的计算, 该方法的训练开销较低且兼容性强, 可以与其他控制模块ControlNet一起使用.
LORA
经常使用生成式AI相关应用的肯定对这个词不陌生。

LoRA模型,全称Low-Rank Adaptation of Large Language Models,是一种用于微调大型语言模型的低秩适应技术。它最初应用于NLP领域,特别是用于微调GPT-3等模型。LoRA通过仅训练低秩矩阵,然后将这些参数注入到原始模型中,从而实现对模型的微调。这种方法不仅减少了计算需求,而且使得训练资源比直接训练原始模型要小得多,因此非常适合在资源有限的环境中使用。 在Stable Diffusion(SD)模型的应用中,LoRA被用作一种插件,允许用户在不修改SD模型的情况下,利用少量数据训练出具有特定画风、IP或人物特征的模型。这种技术在社区使用和个人开发者中非常受欢迎。例如,可以通过LoRA模型改变SD模型的生成风格,或者为SD模型添加新的人物/IP。 LoRA模型的使用涉及安装插件和配置参数。用户需要下载适合的LoRA模型和相应的checkpoint模型,并将其安装到相应的目录。在使用时,可以将LoRA模型与大模型结合使用,通过调整LoRA的权重来控制生成图片的结果。LoRA模型的优点包括训练速度快、计算需求低、训练权重小,因为原始模型被冻结,我们注入新的可训练层,可以将新层的权重保存为一个约3MB大小的文件,比UNet模型的原始大小小了近一千倍。
博文参考|学习推荐
文章: