动手学Agent
推荐一个Datawhale开源项目,体系学习,动手实现一个简单Agent架构:HelloAgent
具体的编码实现项目中非常详细,本博文中我只尝试做一个设计思想整理。
延伸阅读:
- LangChain: Getting Started with Agents - 主流Agent框架的实现细节
- AutoGPT: Autonomous GPT-4 Agent - 首个自主Agent的探索
- BabyAGI: Task-driven Autonomous Agent - 任务驱动的自主Agent实现
Agent经典范式
1. ReAct范式(Reasoning and Acting)
最基础、应用最广的范式,是目前绝大多数 Agent 的基石。
它模仿人类解决问题的直觉:先思考(Thought),再行动(Action),最后观察结果(Observation)。
核心思想解析
ReAct的精髓在于将"推理"(Reasoning)和"行动"(Acting)融合在同一循环中。这与传统程序设计的"分析-执行"分离模式截然不同。
想象一下人类解决数学应用题的过程:
- 阅读题目(理解问题)
- 思考需要什么条件(Thought)
- 列出已知和未知的量(分析)
- 应用公式计算(Action)
- 验证结果是否合理(Observation)
- 如果不合理,调整思路重新计算(循环)
ReAct范式正是将这种人类自然的解决问题方式形式化,让LLM能够像人类一样"边想边做"。
逻辑链路
传统LLM是一问一答。ReAct引入了一个循环(Loop)
$$用户输入 \xrightarrow{思考} 行为 \xrightarrow{观察} 再次思考 \dots 直到得出答案$$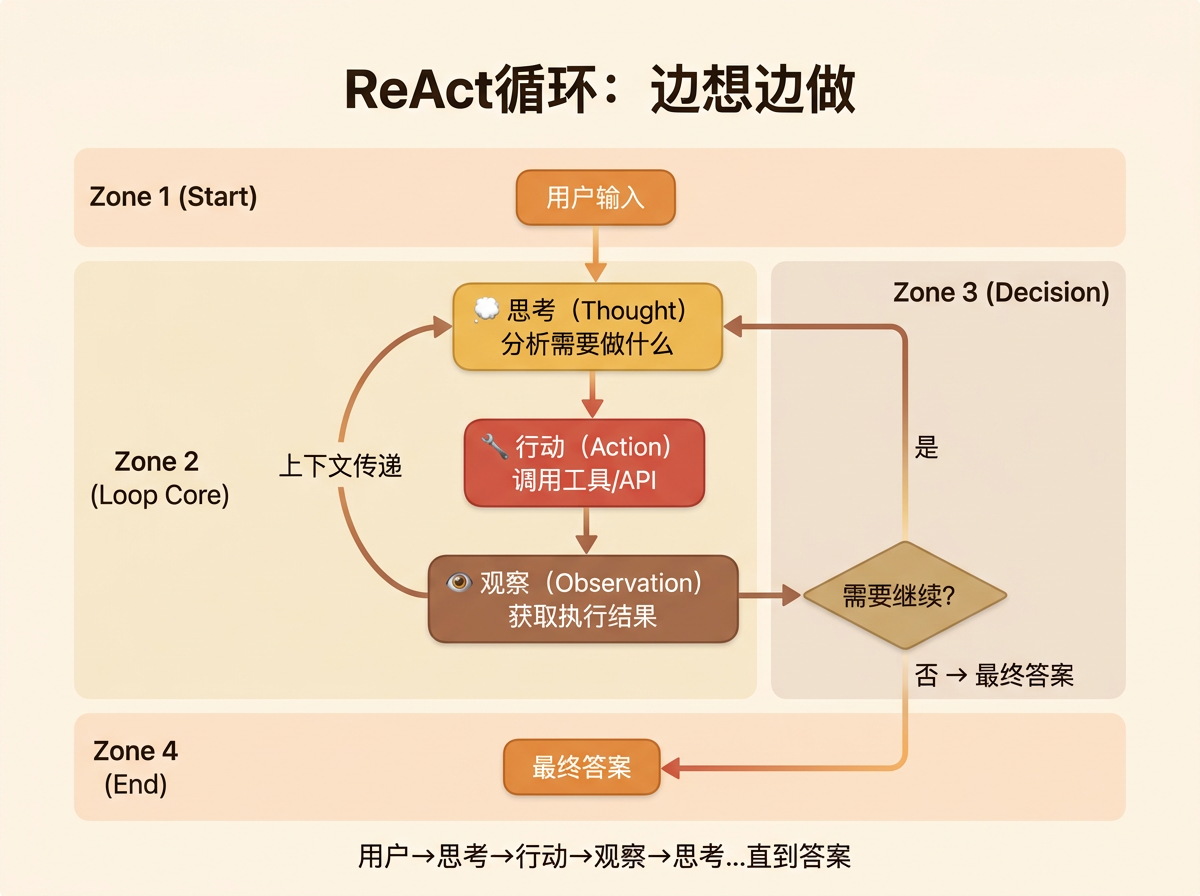
每个步骤都有明确的输入输出:
| 阶段 | 输入 | 处理逻辑 | 输出 |
|---|---|---|---|
| Thought | 上下文 + 当前任务 | LLM推理需要做什么 | 下一步行动的意图 |
| Action | Thought意图 | 解析并调用相应工具 | 工具执行请求 |
| Observation | 工具执行返回 | 格式化工具输出 | 事实性结果数据 |
| 决策 | Observation + 目标 | 判断是否完成任务 | 继续/结束 |
适用场景:绝大多数调用工具的短链路任务,如实时搜索、数据库查询、查天气、订机票等。
缺点:Token 消耗大且易迷路。
在复杂长任务或者长链路中,模型容易在反复的循环中忘记最初的目标(上下文漂移),或者陷入无限死循环。
流程示例
- 用户输入:“上海明天的天气适合穿短袖吗?”
- Thought:我需要先查上海明天的气温,然后再判断是否适合短袖。
- Action:调用
weather_api(location="shanghai", date="tomorrow")。 - Observation:返回 15°C - 22°C,有阵雨。
- Thought:气温偏凉且有雨,不适合穿短袖,建议长袖加外套。
- Final Answer:不适合,建议穿长袖…
代码逻辑
LLM节点和工具节点之间的无限乒乓球,直到LLM决定停止(或达到最大预设次数)
| |
延伸阅读:
2. Plan-and-Execute 范式(规划与执行)
针对ReAct容易"走一步看一步"导致跑偏的问题,这种范式把"规划"和"执行"拆分开。
核心逻辑:先做任务规划,再逐个击破。通常由两个逻辑单元(Planner和Executor)组成。
设计思想解析
Plan-and-Execute范式借鉴了软件工程中的"分离关注点"(Separation of Concerns)原则。
想象一个项目经理解决复杂问题的过程:
- 规划阶段:项目经理(Planner)先分析任务需求,制定详细的执行计划,确定每个步骤的顺序和依赖关系
- 执行阶段:工程师(Executor)按照计划逐个实施,每完成一步汇报进度
- 监控阶段:项目经理监控执行进度,遇到偏差时调整计划(Re-planning)
这种方式的优势在于:
- 全局视角:Planner能够从全局角度评估任务的完整性和合理性
- 可追溯性:每一步都有明确的计划和执行记录,便于调试和优化
- 并行能力:独立步骤可以并行执行,提高效率
- 容错机制:某一步失败时,可以精准定位问题并回滚重试
架构组成
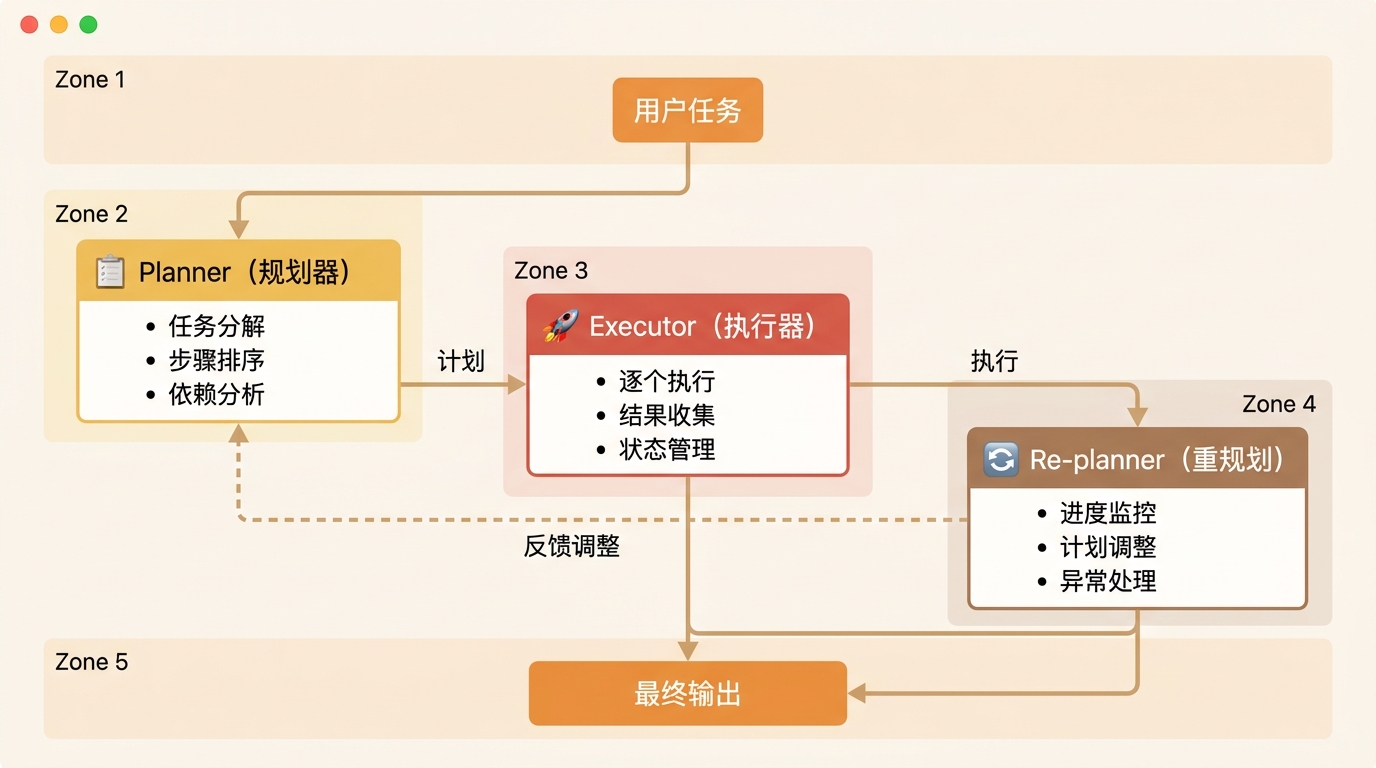
| 组件 | 职责 | 能力要求 |
|---|---|---|
| Planner | 任务分解、步骤排序、依赖分析 | 强推理能力、全局视角 |
| Executor | 单步执行、结果收集、状态管理 | 强工具调用能力、稳定性 |
| Re-planner | 进度监控、计划调整、异常处理 | 强判断能力、灵活性 |
适用场景:撰写研报、多步骤跨平台操作等任务步骤明确、流程较长、逻辑复杂的任务。
缺点:响应延迟(Latency)高。由于需要先做完整的规划,用户的第一反馈会很慢;且如果初始规划失误,后续步骤可能全是无效功。
流程示例
- 用户输入:“分析特斯拉和比亚迪的财报并对比写一份 PPT 提纲。”
- Planner (规划阶段):生成步骤列表:
- ① 搜索特斯拉财报
- ② 搜索比亚迪财报
- ③ 提取关键数据
- ④ 生成对比表格
- ⑤ 撰写提纲
- Executor (执行阶段):依次调用 ReAct 模式完成 ① 至 ⑤。
- Re-planner (重评阶段):检查结果,如果发现步骤 ② 没搜到数据,则修改计划重新搜索。
代码逻辑
for循环+队列,生成清单->消费清单,清单可以线性执行,部分不依赖前面内容的也可以并行执行。
Tip 每一个清单(执行器)单元也可以是一个单个的拥有独立调用工具能力的Agent。
| |
延伸阅读:
3.Reflection/Self-Correction范式(反思与修正)
为了让Agent不仅"做完",还能"做好",引入了类似人类的"自我审查"机制。
全称:Reasoning with Reflection (反思增强)
核心思想解析
Reflection范式体现了人类追求卓越的"批判性思维"(Critical Thinking)。
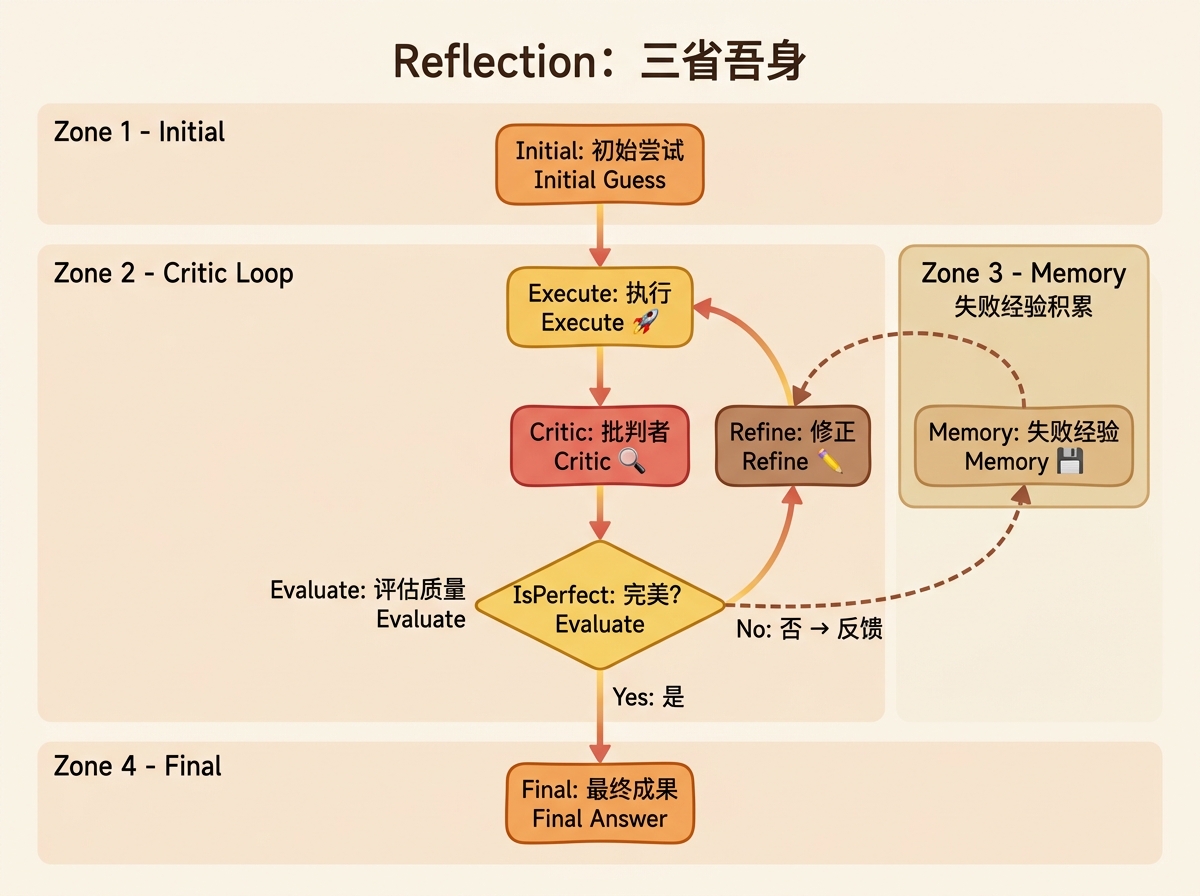
想象一个写作者打磨作品的过程:
- 初稿:快速写出第一版内容
- 自我审阅:从读者角度审视,发现问题点
- 批判反馈:指出逻辑漏洞、表达不当、事实错误
- 修改完善:基于反馈进行针对性修改
- 迭代优化:重复审阅-修改循环,直到满意
这种方式的价值在于:
- 质量保障:通过多轮检查,提升最终产出的准确性和质量
- 错误自愈:能够自主发现并修复错误,减少人工干预
- 学习积累:将失败经验内化为知识,提升未来表现
- 容错增强:允许初始尝试不够完美,通过迭代达到目标
实现模式
Reflection有多种实现方式:
| 模式 | 批判者类型 | 适用场景 | 优势 |
|---|---|---|---|
| 自反思 | 同一模型生成反馈 | 通用任务 | 简单易实现 |
| 交叉反思 | 不同模型互检 | 高精度任务 | 客观性强 |
| 工具反思 | 静态分析工具 | 代码/数学任务 | 精确可靠 |
| 人类反思 | 人工审核 | 关键决策 | 最终保障 |
应用场景:长文本生成、代码生成、翻译优化。
缺点:成本极高。为了得到一个正确答案,可能需要消耗 3-5 倍的 Token 和计算时间。
流程示例
- 执行:模型生成一段处理数据的 Python 代码。
- 测试:代理层在沙箱运行代码,报错
IndexError。 - Reflection:模型分析报错原因:“我在处理空列表时没有判断长度。”
- Refine:模型参考失败经验,生成修正后的代码并再次测试。
代码逻辑
Tip 这里的批判者(Critic)往往可能会使用不同的模型或者不同的Agent来做交叉验证。
| |
延伸阅读:
如何选取合适的范式
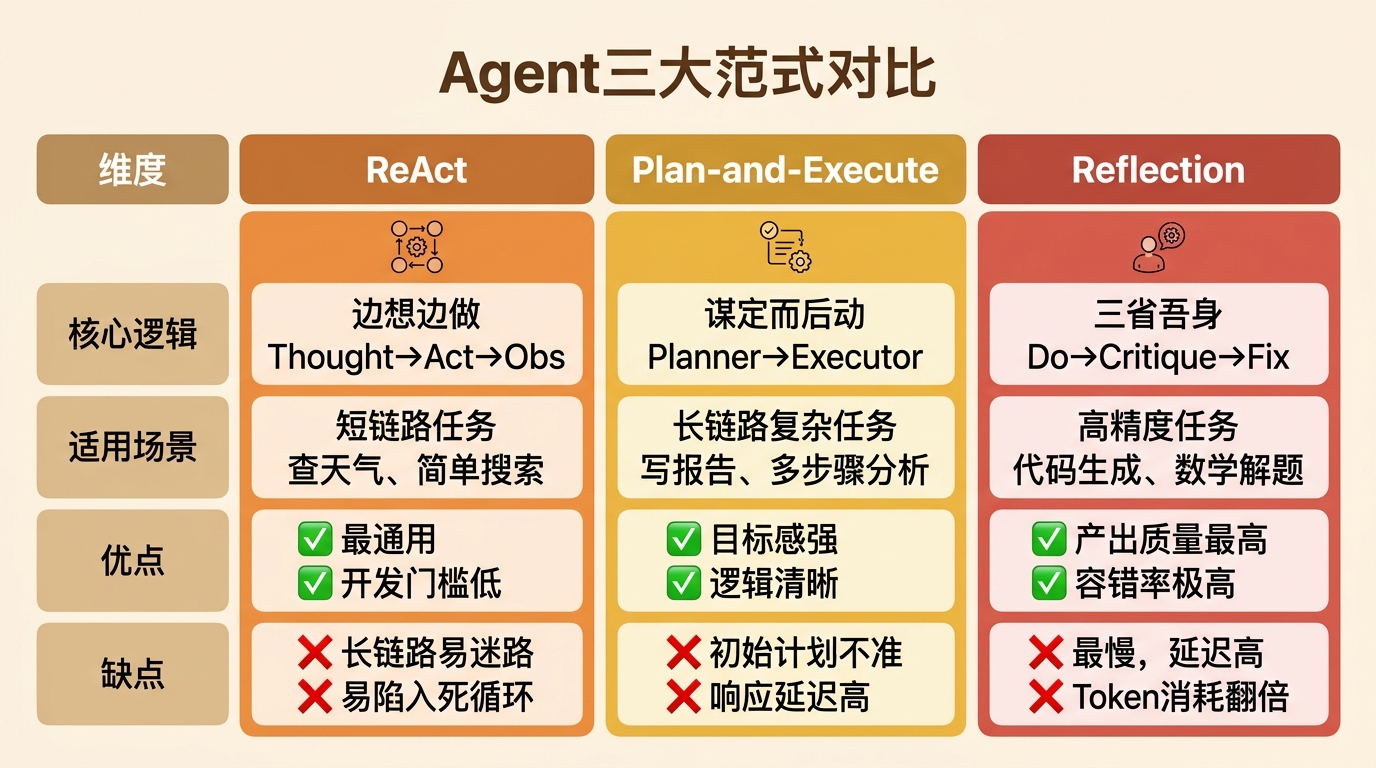
| 范式名称 | 核心逻辑 (Motto) | 适用场景 (Best For) | 优点 | 缺点 (Cons) | 开发复杂度 | 成本/延迟 |
|---|---|---|---|---|---|---|
| ReAct (Reason+Act) | “边想边做” (Thought→Act→Obs) | 通用型 查天气、简单搜索、单次工具调用 | ✅ 最通用,生态支持最好。 ✅ 开发门槛低,上手快。 | ❌ 长链路任务容易"迷路" ❌ 容易陷入死循环 | ★ | 低 |
| Plan-and-Execute (规划与执行) | “谋定而后动” (Planner→Executor) | 长链路复杂任务 写长短报告、从零完成项目、多步骤数据分析 | ✅ 目标感强,不易跑偏。 ✅ 逻辑清晰,步骤可控。 | ❌ 初始计划可能不准确。 ❌ 灵活性稍差(除非加 Re-planning) | ★★ | 中 |
| Reflection (反思/自修正) | “三省吾身” (Do→Critique→Fix) | 高精度任务 写代码(Code Gen)、数学解题、翻译优化 | ✅ 产出质量最高。 ✅ 容错率极高,能自动修 Bug。 | ❌ 最慢,延迟高。 ❌ Token 消耗翻倍(反复重试) | ★★ | 高 |
Tip 现代Agent开发过程中,几种范式常常搭配起来使用。
| 架构类型 | 组合方式 | 具体实现逻辑 |
|---|---|---|
| 最强单体架构 | ReAct + Reflection | 让 Agent 以 ReAct(边想边做:Thought→Act→Obs) 的方式调用工具,但在输出最终答案前,增加一个 Reflection(反思:Do→Critique→Fix) 节点检查成果,兼顾灵活性与质量。 |
| 最强任务架构 | Plan-and-Execute (外层) + ReAct (内层) | 1. 外层 Planner 负责制定整体计划:①搜索信息 ②整理数据 ③写邮件;2. 内层 Executor 是一个 ReAct Agent,专门执行具体步骤(如"搜索信息"这一环节),兼顾规划性与执行灵活性。 |
| 终极架构 | Plan-and-Execute + ReAct + Reflection | 最强大的混合架构:Planner规划全局→ReAct执行各步→Reflection全局质检,适用于最复杂的任务场景,如自动化研究报告生成。 |
组合架构的核心是**“分工协同”**:通过不同范式的优势互补,解决单一范式的短板(如 ReAct 长链路易迷路、Plan-and-Execute 灵活性差、Reflection 速度慢等问题)。
开发复杂度与成本/延迟会随组合层数增加而上升,但任务完成质量与鲁棒性也会提升,需根据实际场景权衡。
延伸阅读:
- LangGraph: Stateful Agents for Complex Workflows - 组合范式的高级框架
- Semantic Kernel: Orchestrate AI Skills - 微软的技能编排框架
- AI Agents: A Survey - Agent架构综合调研